本文由DeepL翻译 原文地址见末尾
Go中的通道机制是相当强大的,但了解内在的概念甚至可以使其更加强大。事实上,选择一个有缓冲或无缓冲的通道将改变应用程序的行为以及性能。
无缓冲channel
一个无缓冲的通道是一个一旦有消息发射到该通道就需要一个接收器的通道。要声明一个无缓冲的通道,你只需不声明容量。下面是一个例子。
package main
import (
"sync"
"time"
)
func main() {
c := make(chan string)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
c <- foo
}()
go func() {
defer wg.Done()
time.Sleep(time.Second * 1)
println(Message: + <-c)
}()
wg.Wait()
}第一个goroutine在发送消息foo后被阻塞了,因为还没有接收者准备好。这种行为在规范中得到了很好的解释。
如果容量为零或没有,信道是无缓冲的,只有当发送方和接收方都准备好时,通信才会成功。
在golang的文档也很清楚地说明了这一点。
如果信道是无缓冲的,那么发送方就会阻断,直到接收方收到值为止。
一个通道的内部表示可以提供关于这种行为的更多有趣的细节。
内部结构
通道结构 hchan 在运行时包的 chan.go 中可用。该结构包含与通道的缓冲区有关的属性,但为了说明无缓冲通道,我将省略那些我们将在后面看到的属性。下面是无缓冲通道的表示。
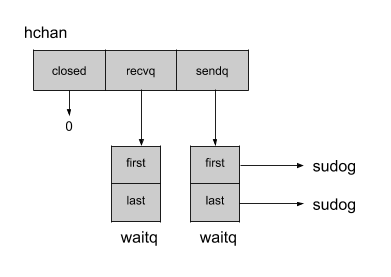
通道保持指向接收方recvq和发送方sendq的指针,由链表waitq表示。sudog包含指向下一个和上一个元素的指针以及处理接收方/发送方的goroutine的相关信息。有了这些信息,Go就可以很容易地知道,如果一个发送者失踪了,通道什么时候应该阻止一个接收者,反之亦然。
下面是我们之前的例子的工作流程。
- 该通道是以一个空的接收者和发送者列表创建的。
- 我们的第一个goroutine向通道发送值foo,第16行。
- 该通道从一个池中获得了一个结构sudog,它将代表发送者。这个结构将保持对goroutine和值foo的引用。
- 这个发件人现在被排在sendq属性中。
- goroutine进入等待状态,原因是 “chan send”。
- 我们的第二个goroutine将从通道中读取一个消息,第23行。
- 频道将从sendq列表中解锁,以获得等待中的发送者,该发送者由步骤3中的结构代表。
- 该通道将使用memmove函数将发送者发送的值复制到我们读取通道的变量中,该值被包装成sudog结构。
- 我们在第5步中停放的第一个goroutine现在可以继续,并将释放在第3步中获得的sudog。
正如我们在工作流程中再次看到的那样,goroutine必须切换到等待,直到有一个接收器可用。然而,如果需要的话,由于有了缓冲通道,这种阻塞行为是可以避免的。
有缓冲channel
我将略微修改前面的例子,以便增加一个缓冲区。
package main
import (
"sync"
"time"
)
func main() {
c := make(chan string, 2)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
c <- foo
c <- bar
}()
go func() {
defer wg.Done()
time.Sleep(time.Second * 1)
println(Message: + <-c)
println(Message: + <-c)
}()
wg.Wait()
}现在让我们根据这个例子来分析与缓冲区有关的字段的结构hchan。
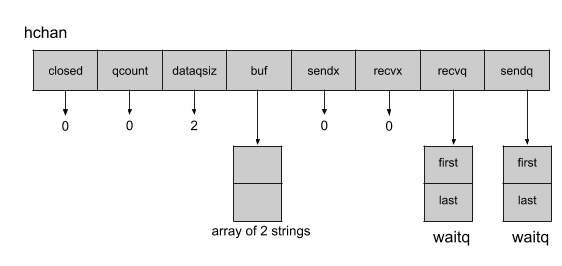
缓冲区由五个属性组成。
- qcount存储缓冲区内的当前元素数
- dataqsiz存储缓冲区中的最大元素数
- buf指向一个内存段,该内存段包含缓冲区中最大元素数的空间。
- sendx存储通道要接收的下一个元素在缓冲区的位置
- recvx存储下一个元素在缓冲区中的位置,由通道返回。
由于sendx和recvx的存在,缓冲区的工作方式就像一个循环队列。
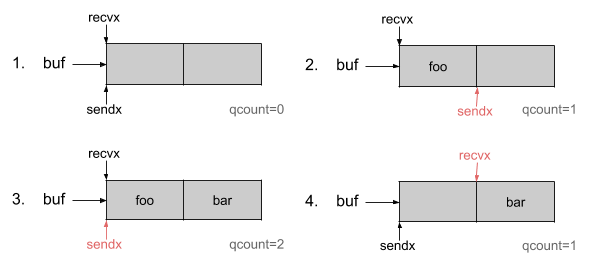
循环队列允许我们保持缓冲区内的秩序,而不需要在其中一个元素从缓冲区中跳出时不断转移。
一旦达到缓冲区的极限,试图在缓冲区推送一个元素的goroutine将在发送者列表中被移动,并切换到等待状态,正如我们在上一节所看到的。然后,一旦程序将读取缓冲区,位于缓冲区recvx位置的元素将被返回,等待的goroutine将恢复,其值将被推入缓冲区。这些优先级允许通道保持先入先出的行为。
由于缓冲区大小不足而导致的延迟
我们在创建通道时定义的缓冲区的大小可能会极大地影响性能。我将使用密集使用通道的扇出模式,以便看到不同缓冲区大小的影响。下面是一些基准测试。
package bench
import (
"sync"
"sync/atomic"
"testing"
)
func BenchmarkWithNoBuffer(b *testing.B) {
benchmarkWithBuffer(b, 0)
}
func BenchmarkWithBufferSizeOf1(b *testing.B) {
benchmarkWithBuffer(b, 1)
}
func BenchmarkWithBufferSizeEqualsToNumberOfWorker(b *testing.B) {
benchmarkWithBuffer(b, 5)
}
func BenchmarkWithBufferSizeExceedsNumberOfWorker(b *testing.B) {
benchmarkWithBuffer(b, 25)
}
func benchmarkWithBuffer(b *testing.B, size int) {
for i := 0; i < b.N; i++ {
c := make(chan uint32, size)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
for i := uint32(0); i < 1000; i++ {
c <- i%2
}
close(c)
}()
var total uint32
for w := 0; w < 5; w++ {
wg.Add(1)
go func() {
defer wg.Done()
for {
v, ok := <-c
if !ok {
break
}
atomic.AddUint32(&total, v)
}
}()
}
wg.Wait()
}
}在我们的基准中,一个生产者将在通道中注入一百万个整数元素,而十个工作者将读取并将它们添加到一个名为total的结果变量中。
我将运行它们十次,并通过 benchstat 分析结果。
name time/op
WithNoBuffer-8 306µs ± 3%
WithBufferSizeOf1-8 248µs ± 1%
WithBufferSizeEqualsToNumberOfWorker-8 183µs ± 4%
WithBufferSizeExceedsNumberOfWorker-8 134µs ± 2%一个大小适中的缓冲区确实可以使你的应用程序更快 让我们分析一下我们的基准测试的痕迹,以确认延迟的位置。
追踪延时
追踪你的基准会让你获得一个同步阻塞配置文件,显示goroutines在同步原语上的阻塞等待是在哪里。Goroutines花了9ms的时间在同步阻塞上,等待来自未缓冲通道的一个值,而一个50大小的缓冲区只等待了1.9ms。

由于有了缓冲器,这里的延迟被除以5。
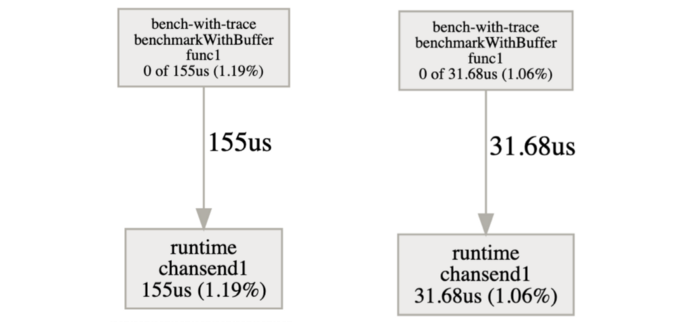
我们现在确实证实了我们之前的疑虑。缓冲区的大小对我们的应用性能起着重要作用。
原文地址: https://medium.com/a-journey-with-go/go-buffered-and-unbuffered-channels-29a107c00268